让不懂建站的用户快速建站,让会建站的提高建站效率!


好意思东时辰周二宁波在线配资门户平台_股票配资行情与资讯,谷歌发布了一个炸裂硅谷科技圈的最新算法:超高效AI内存压缩算法TurboQuant。

谷歌宣称,这项算法不错在不死亡准确性的前提下,将大型言语模子入手时的缓存内存占用至少减少6倍、性能提高8倍,执行上,不错让东说念主工智能在占用更少内存空间的同期记着更多信息。
这一算法已经发布,好意思股芯片股应声下挫。谷歌和华尔街也掀翻了一场激烈参议:面前困扰繁密科技巨头的内存芯片穷乏糟糕是否不错就此驱逐了?
TurboQuant是什么?
先来说说这项TurboQuant算法具体是什么。
凭证谷歌在官方网站的先容,TurboQuant是一种压缩设施,它大致在不死亡任何精度的前提下大幅减小模子大小,因此特地符合支撑键值缓存(KV Cache)压缩和向量搜索。它通过两个关节体式终局这一丝:
1、高质料压缩(PolarQuant method):TurboQuant 领先飞速旋转数据向量。这一玄妙的体式简化了数据的几何结构,使得不错沉着地将范例的高质料量化器分袂应用于向量的每个部分。第一阶段期骗了大部分压缩技艺(大部分比特)来保留原始向量的主要观念和特征。
2、摒除荆棘罪状:TurboQuant 使用小数剩余的压缩技艺(仅1比特)将QJL算法应用于第一阶段留传的细微罪状。QJL 阶段充任数学罪状检讨器,摒除偏差,从而赢得更准确的能干力评分。
通俗来说,TurboQuant执行上便是在保合手AI模子中枢结构不变的情况下压缩AI模子,况兼无需预处置或特定的校准数据。
谷歌宣称,他们使用开源的长落魄文模子(Gemma和Mistral ),在包括LongBench、Needle In A Haystack、ZeroSCROLLS、RULER和L-Eval在内的多项基准测试中,对 TurboQuant、PolarQuant 和KIVI这三种算法进行了严格评估。
实验数据标明,TurboQuant在点积失真和调回率方面均达到了最优评分性能,同期最大划定地减少了键值(KV)内存占用。
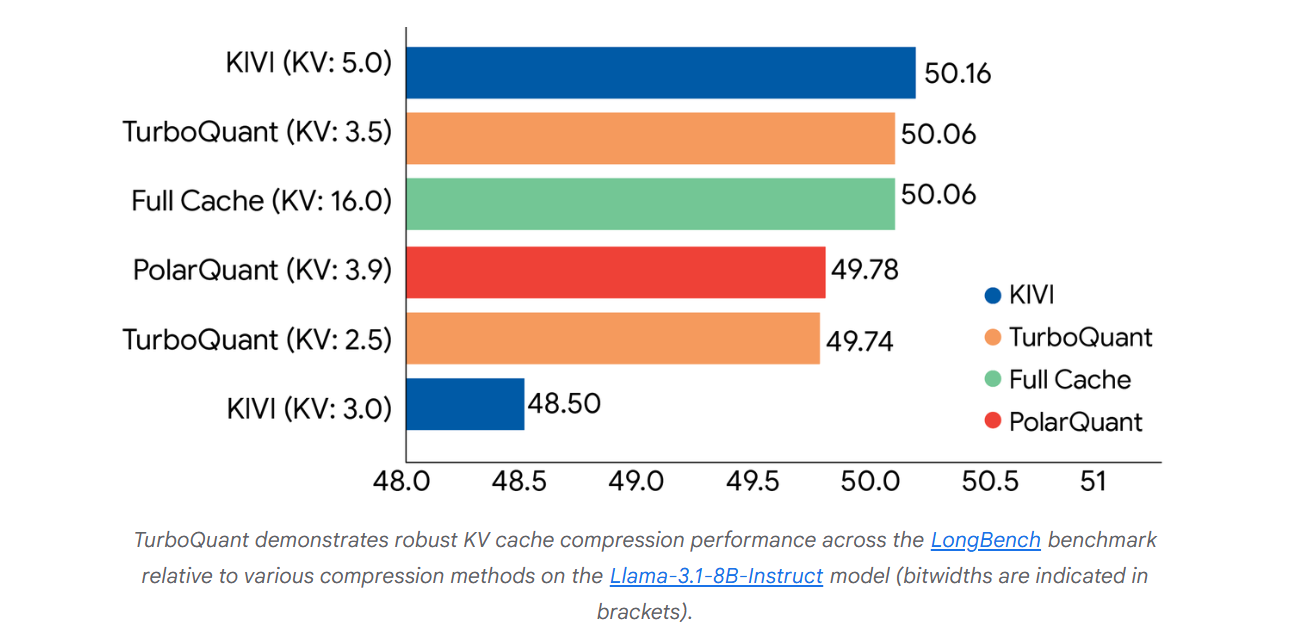
上图展示了TurboQuant、PolarQuant 和KIVI基线算法在问答、代码生成和节录等不同任务中的概括性能得分。
谷歌称,TurboQuant在通盘基准测试中均取得了完竣的卑劣隔断,同期将键值内存大小至少减少了6倍。
他们筹议不才个月的ICLR 2026会议上展示他们的连络后果,以及展示终局这种压缩的两种设施:量化设施PolarQuant和名为QJL的进修和优化设施。
谷歌迎来DeepSeek时刻?
谷歌的这一算法,令不少东说念主联念念到了HBO电视剧《硅谷》(2014年至2019年播出)中造谣的创业公司Pied Piper。在电视剧中,Pied Piper一样诱惑出一种打破性的压缩算法,能在近乎无损压缩的情况下大幅减小文献大小。
而现实中的谷歌连络院发布的TurboQuant技艺,一样努力于在不死亡质料的前提下终局极致压缩,但它应用于东说念主工智能系统的中枢瓶颈。
Cloudflare首席实施官Matthew Prince等东说念主以至称之为谷歌的DeepSeek时刻,合计其有望像DeepSeek一样,通过极高的遵守收益大幅拉低AI的入手资本,同期在隔断上保合手竞争力。
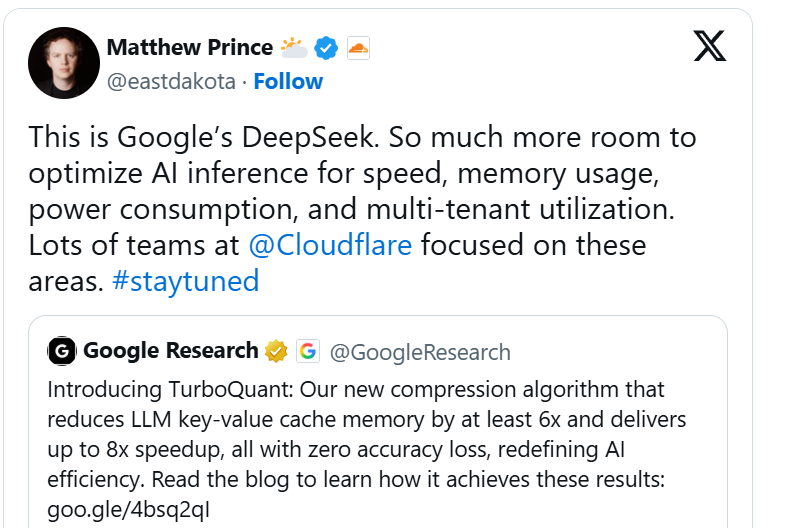
他在X上的一篇著述中写说念:“在速率、内存使用、功耗和期骗率方面,AI推理还有很大的优化空间。”
内存芯片需求将会降温?
谷歌的这一算法发布之际,恰恰群众存储芯片穷乏问题日趋严峻的时刻。
由于群众各大巨头全力营建AI基础设施,内存需求束缚攀升,供不应求的表象短期内难以缓解。各大科技公司诱惑东说念主员已经念念出多样翻新设施来克服或至少叮嘱内存穷乏,而谷歌的TurboQuant,咫尺被科技界东说念主士合计,很可能成为一种给内存需求降温的可合手续决策。
这一预期关于努力于建设AI基础设施的科技巨头们来说,当然是一件功德。但关于内存芯片厂商们来说,可能隔断就不同了。
受到内存需求可能降温预期的影响,好意思东时辰周三,好意思股存储芯片板块在开盘后不久就集体跳水:闪迪一度跌6.5%,好意思光科技跌4%,西部数据跌超4%,希捷科技跌超5%。
闪迪周三早盘一度大跌
周四亚洲时段,适度发稿时SK海力士下落4.42%,三星跌3.02%。
Futurum股票连络部门的Shay Boloor宣称:
“市集合计这对内存类股票来说是一个潜在的不利身分,因为长落魄文AI推理每个责任负载可能需要的内存当今可能大幅减少。”
大摩提议相背不雅点
不外,也有华尔街巨头提议了相背的看法。
比如,Lynx Equity Strategies分析师KC Rajkumar就提议,TurboQuant的技艺“颠覆性”可能并莫得媒体态状的那么夸张。
他暗意,谷歌所谓的“8倍性能提高”是建立在与老旧的32-bit模子对比之上的,关联词面前的推理模子早已平庸聘任4-bit量化数据,因此性能提高幅度并莫得那么夸张。
此外,摩根士丹利还指出,谷歌TurboQuant技艺仅作用于推理阶段的键值缓存,不影响模子权重所占用的HBM,也与进修任务无关。
因此,这并非存储总需求或硬件总量减少6倍,而是通过遵守提高增多单GPU辩白量——换取硬件可支撑4至8倍更长的落魄文,或在不触发内存溢出的前提下显耀提高批处置界限。
更进犯的是,摩根士丹利进一步征引了“杰文斯悖论”(Jevons Paradox),来阐明内存需求不会降温的判断。
杰文斯悖论是经济学中的一个进犯观念,指的是技艺跳跃与资源耗尽之间的一种反直观相干。其界说是:当技艺跳跃提高了遵守,资源耗尽不仅莫得减少,反而激增。举例,瓦特纠正的蒸汽机让煤炭燃烧愈加高效,但隔断却是煤炭需求飙升。
摩根士丹利合计,通过大幅缩短单次查询的管事资本,TurboQuant大致让正本只可在云表文静集群上入手的模子迁徙至腹地,有用缩短AI界限化部署的门槛,这可能反而能进一步提振合座需求。
执行上,Cloudflare首席实施官Matthew Prince等东说念主提到的DeepSeek,便是杰文斯悖论的最较着例子:在DeepSeek旧年年头刚刚发布时,市集也一度担忧AI硬件需求将会降温,但事实是,遵守的提高带来了AI应用的进一步普及,AI硬件需求也再次升温。

宁波在线配资门户平台_股票配资行情与资讯提示:本文来自互联网,不代表本网站观点。